





- Bandwidth estimation (BWE) and congestion management play an vital position in delivering high-quality real-time communication (RTC) throughout Meta’s household of apps.
- We’ve adopted a machine studying (ML)-based strategy that permits us to resolve networking issues holistically throughout cross-layers reminiscent of BWE, community resiliency, and transport.
- We’re sharing our experiment outcomes from this strategy, a few of the challenges we encountered throughout execution, and learnings for brand spanking new adopters.
Our present bandwidth estimation (BWE) module at Meta is primarily based on WebRTC’s Google Congestion Controller (GCC). Now we have made a number of enhancements by parameter tuning, however this has resulted in a extra complicated system, as proven in Determine 1.
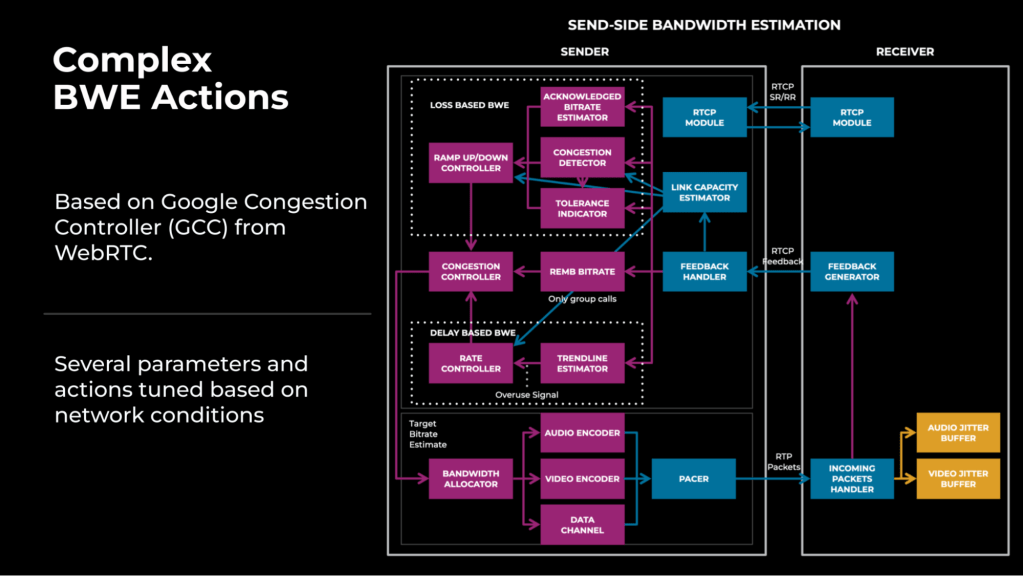
One problem with the tuned congestion management (CC)/BWE algorithm was that it had a number of parameters and actions that had been depending on community circumstances. For instance, there was a trade-off between high quality and reliability; bettering high quality for high-bandwidth customers usually led to reliability regressions for low-bandwidth customers, and vice versa, making it difficult to optimize the person expertise for various community circumstances.
Moreover, we observed some inefficiencies with reference to bettering and sustaining the module with the complicated BWE module:
- As a result of absence of practical community circumstances throughout our experimentation course of, fine-tuning the parameters for person purchasers necessitated a number of makes an attempt.
- Even after the rollout, it wasn’t clear if the optimized parameters had been nonetheless relevant for the focused community varieties.
- This resulted in complicated code logics and branches for engineers to keep up.
To unravel these inefficiencies, we developed a machine studying (ML)-based, network-targeting strategy that gives a cleaner various to hand-tuned guidelines. This strategy additionally permits us to resolve networking issues holistically throughout cross-layers reminiscent of BWE, community resiliency, and transport.
Community characterization
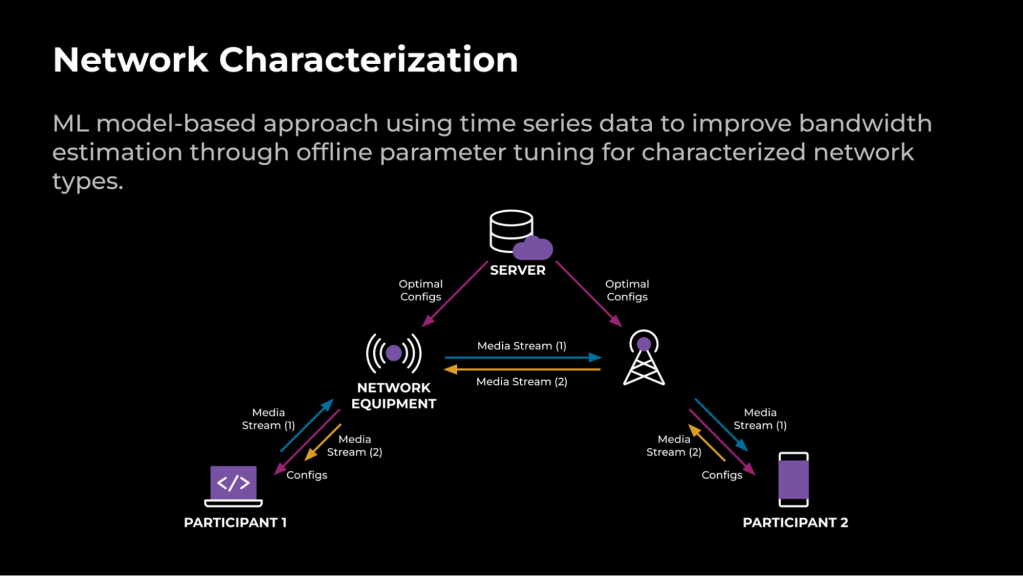
An ML model-based strategy leverages time sequence information to enhance the bandwidth estimation through the use of offline parameter tuning for characterised community varieties.
For an RTC name to be accomplished, the endpoints have to be linked to one another by community units. The optimum configs which have been tuned offline are saved on the server and will be up to date in real-time. Throughout the name connection setup, these optimum configs are delivered to the shopper. Throughout the name, media is transferred instantly between the endpoints or by a relay server. Relying on the community indicators collected through the name, an ML-based strategy characterizes the community into differing kinds and applies the optimum configs for the detected kind.
Determine 2 illustrates an instance of an RTC name that’s optimized utilizing the ML-based strategy.
Mannequin studying and offline parameter tuning
On a excessive degree, community characterization consists of two important elements, as proven in Determine 3. The primary element is offline ML mannequin studying utilizing ML to categorize the community kind (random packet loss versus bursty loss). The second element makes use of offline simulations to tune parameters optimally for the categorized community kind.
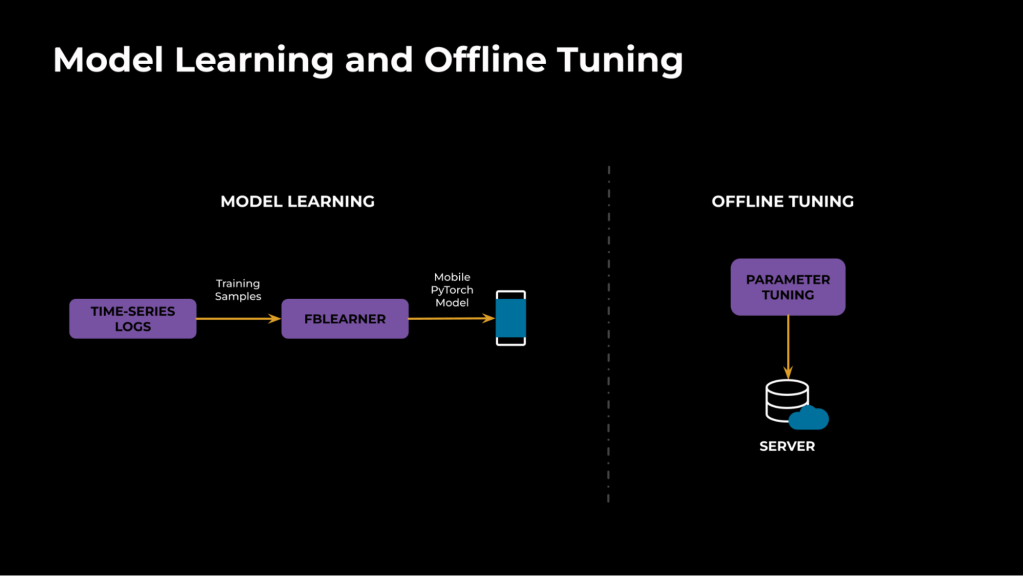
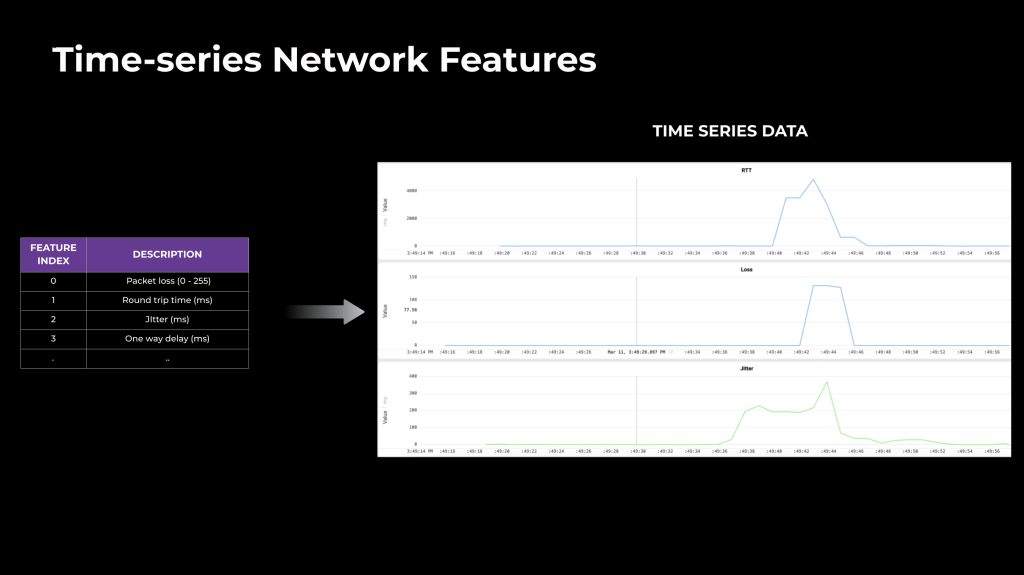
For mannequin studying, we leverage the time sequence information (community indicators and non-personally identifiable info, see Determine 6, under) from manufacturing calls and simulations. In comparison with the mixture metrics logged after the decision, time sequence captures the time-varying nature of the community and dynamics. We use FBLearner, our inner AI stack, for the coaching pipeline and ship the PyTorch mannequin information on demand to the purchasers at the beginning of the decision.
For offline tuning, we use simulations to run community profiles for the detected varieties and select the optimum parameters for the modules primarily based on enhancements in technical metrics (reminiscent of high quality, freeze, and so forth.).
Mannequin structure
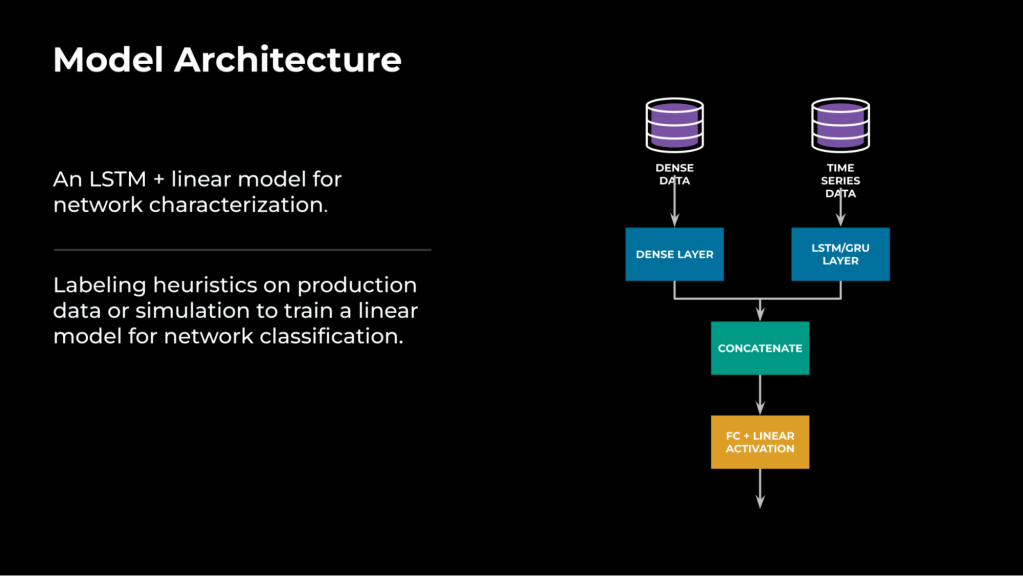
From our expertise, we’ve discovered that it’s essential to mix time sequence options with non-time sequence (i.e., derived metrics from the time window) for a extremely correct modeling.
To deal with each time sequence and non-time sequence information, we’ve designed a mannequin structure that may course of enter from each sources.
The time sequence information will cross by a lengthy short-term reminiscence (LSTM) layer that can convert time sequence enter right into a one-dimensional vector illustration, reminiscent of 16×1. The non-time sequence information or dense information will cross by a dense layer (i.e., a totally linked layer). Then the 2 vectors shall be concatenated, to completely symbolize the community situation prior to now, and handed by a totally linked layer once more. The ultimate output from the neural community mannequin would be the predicted output of the goal/job, as proven in Determine 4.
Use case: Random packet loss classification
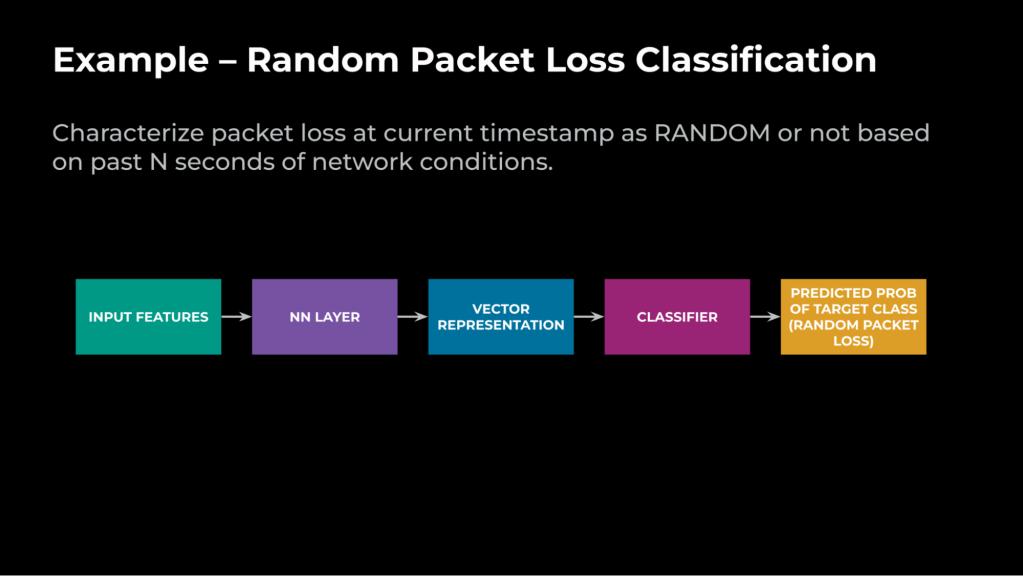
Let’s contemplate the use case of categorizing packet loss as both random or congestion. The previous loss is as a result of community elements, and the latter is as a result of limits in queue size (that are delay dependent). Right here is the ML job definition:
Given the community circumstances prior to now N seconds (10), and that the community is at the moment incurring packet loss, the aim is to characterize the packet loss on the present timestamp as RANDOM or not.
Determine 5 illustrates how we leverage the structure to realize that aim:
Time sequence options
We leverage the next time sequence options gathered from logs:
BWE optimization
When the ML mannequin detects random packet loss, we carry out native optimization on the BWE module by:
- Growing the tolerance to random packet loss within the loss-based BWE (holding the bitrate).
- Growing the ramp-up pace, relying on the hyperlink capability on excessive bandwidths.
- Growing the community resiliency by sending further forward-error correction packets to recuperate from packet loss.
Community prediction
The community characterization downside mentioned within the earlier sections focuses on classifying community varieties primarily based on previous info utilizing time sequence information. For these easy classification duties, we obtain this utilizing the hand-tuned guidelines with some limitations. The true energy of leveraging ML for networking, nonetheless, comes from utilizing it for predicting future community circumstances.
Now we have utilized ML for fixing congestion-prediction issues for optimizing low-bandwidth customers’ expertise.
Congestion prediction
From our evaluation of manufacturing information, we discovered that low-bandwidth customers usually incur congestion as a result of habits of the GCC module. By predicting this congestion, we are able to enhance the reliability of such customers’ habits. In direction of this, we addressed the next downside assertion utilizing round-trip time (RTT) and packet loss:
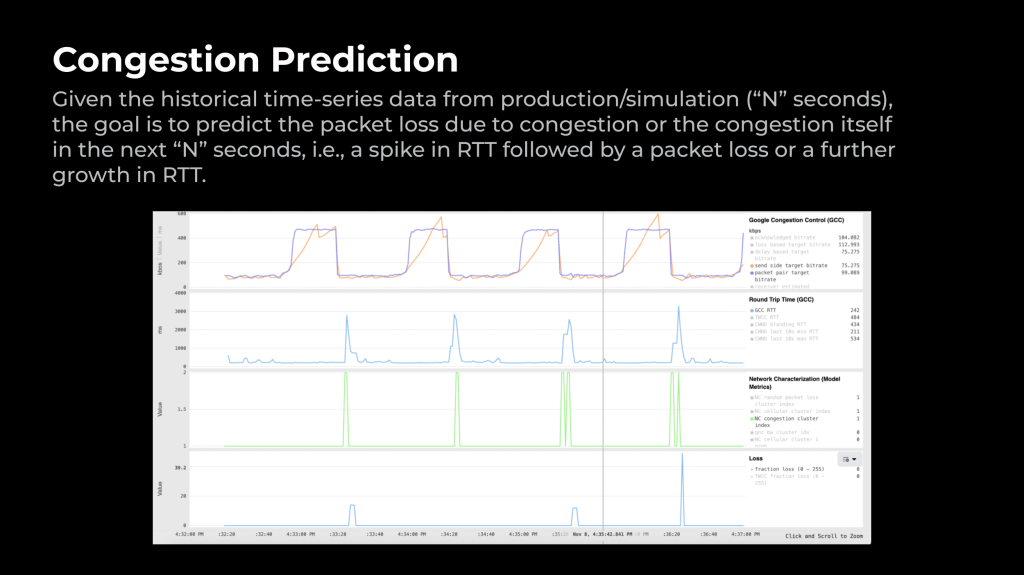
Given the historic time-series information from manufacturing/simulation (“N” seconds), the aim is to foretell packet loss as a consequence of congestion or the congestion itself within the subsequent “N” seconds; that’s, a spike in RTT adopted by a packet loss or an additional development in RTT.
Determine 7 exhibits an instance from a simulation the place the bandwidth alternates between 500 Kbps and 100 Kbps each 30 seconds. As we decrease the bandwidth, the community incurs congestion and the ML mannequin predictions fireplace the inexperienced spikes even earlier than the delay spikes and packet loss happen. This early prediction of congestion is useful in quicker reactions and thus improves the person expertise by stopping video freezes and connection drops.
Producing coaching samples
The primary problem in modeling is producing coaching samples for quite a lot of congestion conditions. With simulations, it’s more durable to seize various kinds of congestion that actual person purchasers would encounter in manufacturing networks. Consequently, we used precise manufacturing logs for labeling congestion samples, following the RTT-spikes standards prior to now and future home windows in accordance with the next assumptions:
- Absent previous RTT spikes, packet losses prior to now and future are impartial.
- Absent previous RTT spikes, we can not predict future RTT spikes or fractional losses (i.e., flosses).
We break up the time window into previous (4 seconds) and future (4 seconds) for labeling.

Mannequin efficiency
Not like community characterization, the place floor reality is unavailable, we are able to get hold of floor reality by analyzing the long run time window after it has handed after which evaluating it with the prediction made 4 seconds earlier. With this logging info gathered from actual manufacturing purchasers, we in contrast the efficiency in offline coaching to on-line information from person purchasers:

Experiment outcomes
Listed below are some highlights from our deployment of varied ML fashions to enhance bandwidth estimation:
Reliability wins for congestion prediction
✅ connection_drop_rate -0.326371 +/- 0.216084
✅ last_minute_quality_regression_v1 -0.421602 +/- 0.206063
✅ last_minute_quality_regression_v2 -0.371398 +/- 0.196064
✅ bad_experience_percentage -0.230152 +/- 0.148308
✅ transport_not_ready_pct -0.437294 +/- 0.400812
✅ peer_video_freeze_percentage -0.749419 +/- 0.180661
✅ peer_video_freeze_percentage_above_500ms -0.438967 +/- 0.212394
High quality and person engagement wins for random packet loss characterization in excessive bandwidth
✅ peer_video_freeze_percentage -0.379246 +/- 0.124718
✅ peer_video_freeze_percentage_above_500ms -0.541780 +/- 0.141212
✅ peer_neteq_plc_cng_perc -0.242295 +/- 0.137200
✅ total_talk_time 0.154204 +/- 0.148788
Reliability and high quality wins for mobile low bandwidth classification
✅ connection_drop_rate -0.195908 +/- 0.127956
✅ last_minute_quality_regression_v1 -0.198618 +/- 0.124958
✅ last_minute_quality_regression_v2 -0.188115 +/- 0.138033
✅ peer_neteq_plc_cng_perc -0.359957 +/- 0.191557
✅ peer_video_freeze_percentage -0.653212 +/- 0.142822
Reliability and high quality wins for mobile excessive bandwidth classification
✅ avg_sender_video_encode_fps 0.152003 +/- 0.046807
✅ avg_sender_video_qp -0.228167 +/- 0.041793
✅ avg_video_quality_score 0.296694 +/- 0.043079
✅ avg_video_sent_bitrate 0.430266 +/- 0.092045
Future plans for making use of ML to RTC
From our venture execution and experimentation on manufacturing purchasers, we observed {that a} ML-based strategy is extra environment friendly in focusing on, end-to-end monitoring, and updating than conventional hand-tuned guidelines for networking. Nevertheless, the effectivity of ML options largely is determined by information high quality and labeling (utilizing simulations or manufacturing logs). By making use of ML-based options to fixing community prediction issues – congestion particularly – we totally leveraged the facility of ML.
Sooner or later, we shall be consolidating all of the community characterization fashions right into a single mannequin utilizing the multi-task strategy to repair the inefficiency as a consequence of redundancy in mannequin obtain, inference, and so forth. We shall be constructing a shared illustration mannequin for the time sequence to resolve completely different duties (e.g., bandwidth classification, packet loss classification, and so forth.) in community characterization. We are going to give attention to constructing practical manufacturing community eventualities for mannequin coaching and validation. It will allow us to make use of ML to determine optimum community actions given the community circumstances. We are going to persist in refining our learning-based strategies to reinforce community efficiency by contemplating present community indicators.





+ There are no comments
Add yours