





- Gradual construct occasions and inefficiencies in packaging and distributing execution recordsdata have been costing our ML/AI engineers a major period of time whereas engaged on our coaching stack.
- By addressing these points head-on, we have been in a position to cut back this overhead by double-digit percentages.
Within the fast-paced world of AI/ML growth, it’s essential to make sure that our infrastructure can sustain with the growing calls for and desires of our ML engineers, whose workflows embrace testing code, writing code, constructing, packaging, and verification.
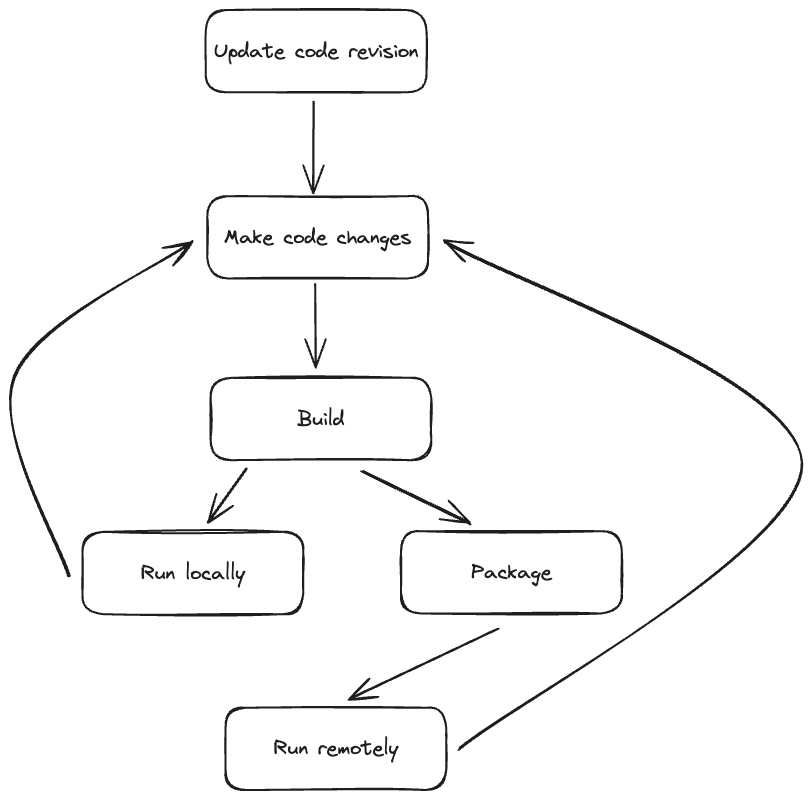
In our efforts to keep up effectivity and productiveness whereas empowering our ML/AI engineers to ship cutting-edge options, we discovered two main challenges that wanted to be addressed head-on: sluggish builds and inefficiencies in packaging and distributing executable recordsdata.
The irritating downside of sluggish builds usually arises when ML engineers work on older (“chilly”) revisions for which our construct infrastructure doesn’t preserve a excessive cache hit fee, requiring us to repeatedly rebuild and relink many elements. Furthermore, construct non-determinism additional contributes to rebuilding by introducing inefficiencies and producing totally different outputs for a similar supply code, making beforehand cached outcomes unusable.
Executable packaging and distribution was one other important problem as a result of, traditionally, most ML Python executables have been represented as XAR recordsdata (self-contained executables) and it isn’t at all times attainable to leverage OSS layer-based options effectively (see extra particulars beneath). Sadly, creating such executables could be computationally expensive, particularly when coping with numerous recordsdata or substantial file sizes. Even when a developer modifies just a few Python recordsdata, a full XAR file reassembly and distribution is usually required, inflicting delays for the executable to be executed on distant machines.
Our aim in enhancing construct velocity was to attenuate the necessity for in depth rebuilding. To perform this, we streamlined the construct graph by lowering dependency counts, mitigated the challenges posed by construct non-determinism, and maximized the utilization of constructed artifacts.
Concurrently, our efforts in packaging and distribution aimed to introduce incrementality assist, thereby eliminating the time-consuming overhead related to XAR creation and distribution.
How we improved construct speeds
To make builds sooner we wished to make sure that we constructed as little as attainable by addressing non-determinism and eliminating unused code and dependencies.
We recognized two sources of construct non-determinism:
- Non-determinism in tooling. Some compilers, equivalent to Clang, Rustc, and NVCC, can produce totally different binary recordsdata for a similar enter, resulting in non-deterministic outcomes. Tackling these tooling non-determinism points proved difficult, as they usually required in depth root trigger evaluation and time-consuming fixes.
- Non-determinism in supply code and construct guidelines. Builders, whether or not deliberately or unintentionally, launched non-determinism by incorporating issues like short-term directories, random values, or timestamps into construct guidelines code. Addressing these points posed the same problem, demanding a considerable funding of time to establish and repair.
Due to Buck2, which sends practically all the construct actions to the Distant Execution (RE) service, we’ve been in a position to efficiently implement non-determinism mitigation inside RE. Now we offer constant outputs for similar actions, paving the way in which for the adoption of a heat and steady revision for ML growth. In observe, this method will eradicate construct occasions in lots of circumstances.
Although eradicating the construct course of from the important path of ML engineers won’t be attainable in all circumstances, we perceive how vital it’s to deal with dependencies for controlling construct occasions. As dependencies naturally elevated, we made enhancements to our instruments for managing them higher. These enhancements helped us discover and take away many pointless dependencies, making construct graph evaluation and total construct occasions significantly better. For instance, we eliminated GPU code from the ultimate binary when it wasn’t wanted and discovered methods to establish which Python modules are literally used and reduce native code utilizing linker maps.
Including incrementality for executable distribution
A typical self-executable Python binary, when unarchived, is represented by hundreds of Python recordsdata (.py and/or .pyc), substantial native libraries, and the Python interpreter. The cumulative result’s a mess of recordsdata, usually numbering within the a whole lot of hundreds, with a complete dimension reaching tens of gigabytes.
Engineers spend a major period of time coping with incremental builds the place packaging and fetching overhead of such a big executable surpasses the construct time. In response to this problem, we applied a brand new answer for the packaging and distribution of Python executables – the Content material Addressable Filesystem (CAF).
The first power of CAF lies in its potential to function incrementally throughout content material addressable file packaging and fetching levels:
- Packaging: By adopting a content-aware method, CAF can intelligently skip redundant uploads of recordsdata already current in Content material Addressable Storage (CAS), whether or not as a part of a special executable or the identical executable with a special model.
- Fetching: CAF maintains a cache on the vacation spot host, making certain that solely content material not already current within the cache must be downloaded.
To optimize the effectivity of this technique, we deploy a CAS daemon on the vast majority of Meta’s knowledge middle hosts. The CAS daemon assumes a number of duties, together with sustaining the native cache on the host (materialization into the cache and cache GC) and organizing a P2P community with different CAS daemon situations utilizing Owl, our high-fanout distribution system for giant knowledge objects. This P2P community permits direct content material fetching from different CAS daemon situations, considerably lowering latency and storage bandwidth capability.
Within the case of CAF, an executable is outlined by a flat manifest file detailing all symlinks, directories, exhausting hyperlinks, and recordsdata, together with their digest and attributes. This manifest implementation permits us to deduplicate all distinctive recordsdata throughout executables and implement a wise affinity/routing mechanism for scheduling, thereby minimizing the quantity of content material that must be downloaded by maximizing native cache utilization.
Whereas the idea could bear some resemblance to what Docker achieves with OverlayFS, our method differs considerably. Organizing correct layers isn’t at all times possible in our case because of the variety of executables with numerous dependencies. On this context, layering turns into much less environment friendly and its group turns into extra advanced to realize. Moreover direct entry to recordsdata is crucial for P2P assist.
We opted for Btrfs as our filesystem due to its compression and talent to put in writing compressed storage knowledge on to extents, which bypasses redundant decompression and compression and Copy-on-write (COW) capabilities. These attributes enable us to keep up executables on block units with a complete dimension just like these represented as XAR recordsdata, share the identical recordsdata from cache throughout executables, and implement a extremely environment friendly COW mechanism that, when wanted, solely copies affected file extents.
LazyCAF and imposing uniform revisions: Areas for additional ML iteration enhancements
The enhancements we applied have confirmed extremely efficient, drastically lowering the overhead and considerably elevating the effectivity of our ML engineers. Quicker construct occasions and extra environment friendly packaging and distribution of executables have lowered overhead by double-digit percentages.
But, our journey to slash construct overhead doesn’t finish right here. We’ve recognized a number of promising enhancements that we goal to ship quickly. In our investigation into our ML workflows, we found that solely a fraction of all the executable content material is utilized in sure situations. Recognizing that, we intend to start out engaged on optimizations to fetch executable elements on demand, thereby considerably lowering materialization time and minimizing the general disk footprint.
We are able to additionally additional speed up the event course of by imposing uniform revisions. We plan to allow all our ML engineers to function on the identical revision, which can enhance the cache hit ratios of our construct. This transfer will additional improve the proportion of incremental builds since many of the artifacts shall be cached.






+ There are no comments
Add yours